|
Abstract:
This new version of Termout has many functions for automatic and
manual terminology processing.
An example of computer assisted terminology,
it lets you work with your specialized corpus
(for now, only in English and Spanish),
to extract terms from it, to evaluate
the extracted candidates, to classify them
in semantic categories, extract definitions
from the corpus, extract equivalents in the other
language, obtain synonyms (term variants)
and even more.
Of course, it also has functions for
terminology database management, and lets you
import an export your database in CSV, HTML and
TBX standards.
The URL is:
http://www.termout.org
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
Contents
I. Introduction
II. Corpus management
-
Upload corpus
-
Manage corpus
-
Tag corpus
-
Index corpus
III. Terminology extraction
-
Extract terms
-
Evaluate results
-
Term record
-
Concordances
IV. Information extraction / enrichment
-
Semantic categories
-
Definitions
-
Bilingual alignment
-
Variants
V. Database management
-
Edit
-
Export
-
Import
Credits
Comments
Donate
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
I. Introduction
Return
Substantial development has taken place in the field Computer-assisted Terminology Processing in the last decades, and terminology professionals are now better equipped to engage in the task of glossary creation. That being said, there is still ample room for improvement. Firstly, there is no tool in the market that can integrate solutions for the different requirements of a terminology project. Secondly, the software currently available for terminology management is time consuming because programs demand repetitive tasks that in many cases could be automatized, and at least a number of these could be addressed by current advances in Natural Language Processing. This would be convenient not only to improve productivity but also to protect users from unnecessary stress and even physical harm due to the time spent sitting in front of a computer and the incessant mechanical repetition of the same hand movements.
In this context, we present an ambitious lexicographic project: to automatize, as much as possible, the different tasks involved in the creation of a specialized dictionary. It is specifically aimed to be used in cases where terminology-related professionals need to generate raw material which they can later improve manually by adding or correcting data, especially in cases where time is of essence.
The program offers solutions for the complete sequence of tasks of a specialized dictionary project, i.e., the tasks of corpus processing (file upload, conversion to plain-text format, language detection, POS-tagging and indexing), terminology extraction (with optional human supervision), information extraction (definitions, equivalence in another language, hyperonymy, synonymy, etc.) and database management (editing, storage, retrieval and export~import options in HTML, CSV and TBX).
The idea is to execute all the tasks in the suggested order, although some users may prefer to do otherwise. For instance, some may instead prefer to upload their own material and use the tool to complement it with information extracted from the corpus. For instance, one could think of a user that has a specific list of terms (or a TBX dictionary) and only wants to extract definitions or equivalences. In the following lines we describe the functions that have been already implemented in the program.
Clarification: We are not a commercial enterprise. We are doing this just out of passion only, because we are terminologists and we love our work.
Disclaimer: You are the only responsible for the safety of your data (corpus and/or database). Remember to back it up periodically.
II. Corpus management
-
Upload corpus: Termout can handle almost every file format there is: txt, pdf, ps, doc, docx, odt, and all html and xml related formats. The user only needs to create a zip file with the corpus and use this upload function. Termout will inflate the zip and analyze each file in the contents. It will guess the file format and convert it to UTF-8 plain-text. It will also detect the language of the documents and even the different fragments of text inside a document. Every text that is not recognized as either English of Spanish will be deleted. At the moment the program only works with these two languages, but we plan to incorporate others in the future. The ideal corpus to analyze with Termout is a scientific journal with at least some 200 texts. Anything less than that would be insufficient for the kind of algorithms that are in place. Figure 1 shows a screenshot of the file-uploading function.
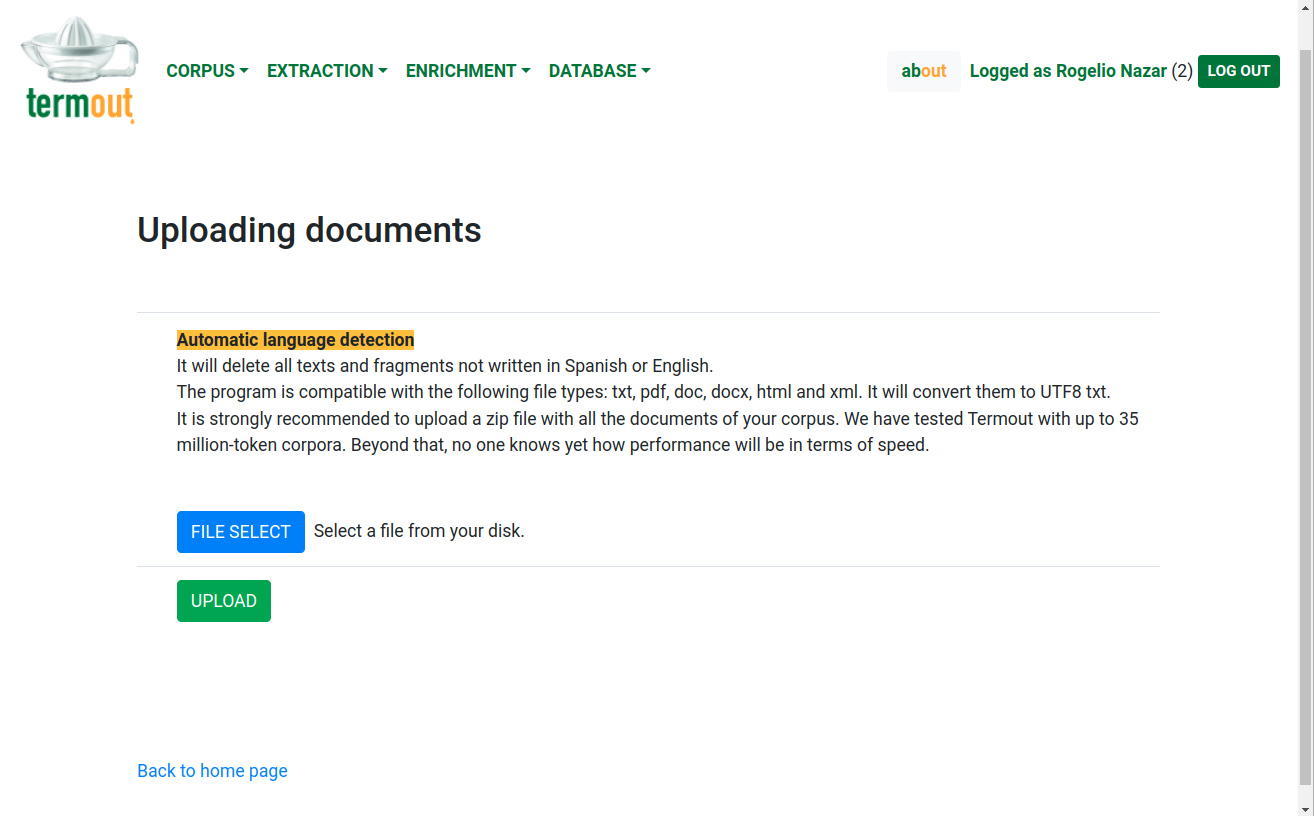
Figure 1: Uploading documents
-
Manage corpus: These functions allow the user to modify the corpus by deleting files or changing their names manually. As shown in Figure 2, users can select files individually or as a group. The language and size of the documents are also provided by the program.
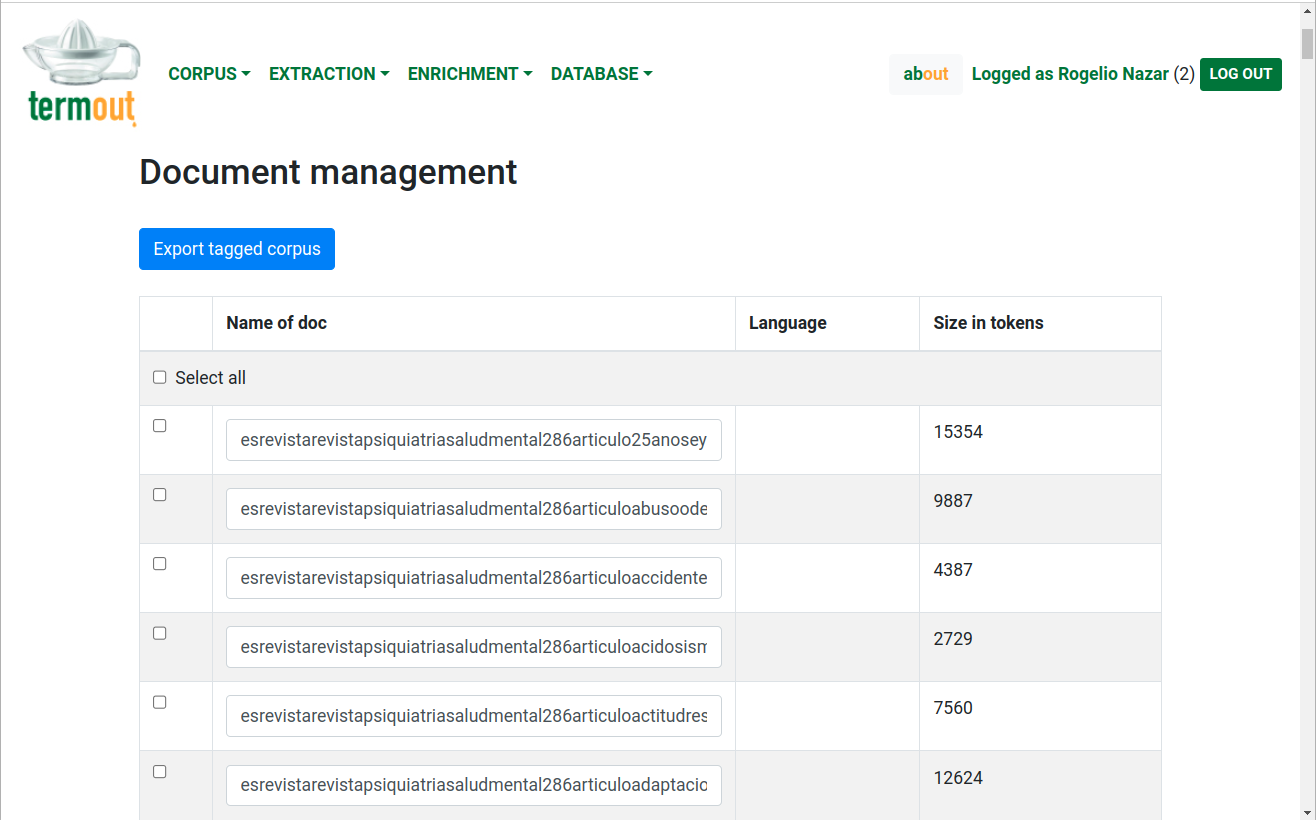
Figure 2: Management of the uploaded files
-
Tag corpus: Once the corpus has been uploaded, this function applies a POS-tagger to the texts. This may take a long time, depending on the corpus' size.
-
Index corpus: This function is necessary for the fast retrieval of concordances, and it is what makes Termout a robust tool to work with large corpora.
III. Terminology extraction
Return
-
Extract terms: Once the corpus has been indexed, it is ready for Termout's main function: to separate the lexical units in the corpus in the categories of terms and non-terms. Users can provide a list of examples of the terms they are interested in, as it may improve results, but this is not mandatory. Termout does not use any form of external resource for this task. All the input for the process is the same analyzed corpus, which is subjected to a series of statistical procedures. Figure 3 presents an animation of this process. Again, this can take considerable time to finish, depending on the size of the corpus.
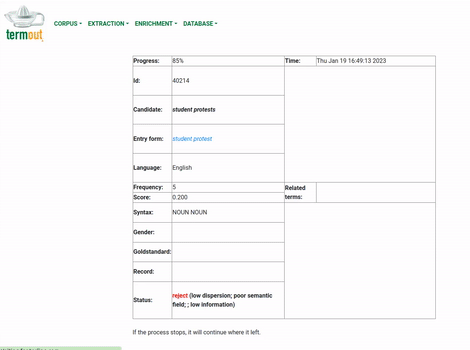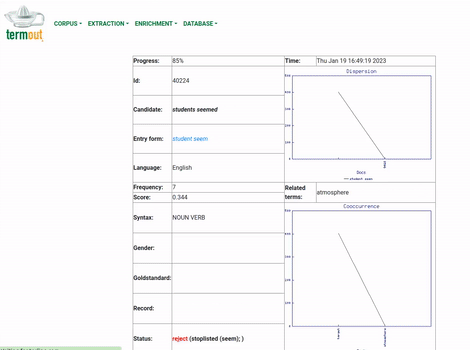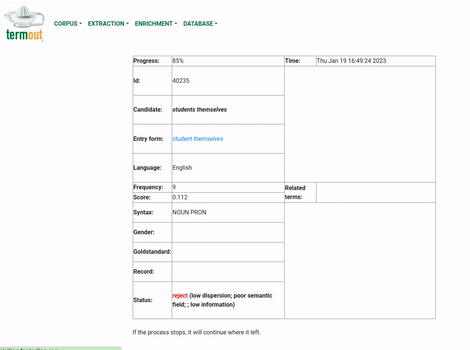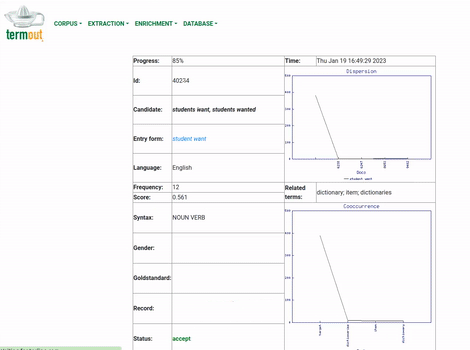
Figure 3: Illustration of the terminology extraction function in Termout
-
Evaluate results: Once the terminology extraction process is finished, users have the possibility to evaluate results. They are presented with two lists: one for those units selected as terms by the program (the 'accepted' list) and another for those considered non-terms (the 'rejected' list). Each unit has a checkbox to allow users to move units from one list to the other. The terms are also separated by language, and they are presented in alphabetical order. Figure 4 shows a case with a corpus of linguistics journals with text in English and Spanish.
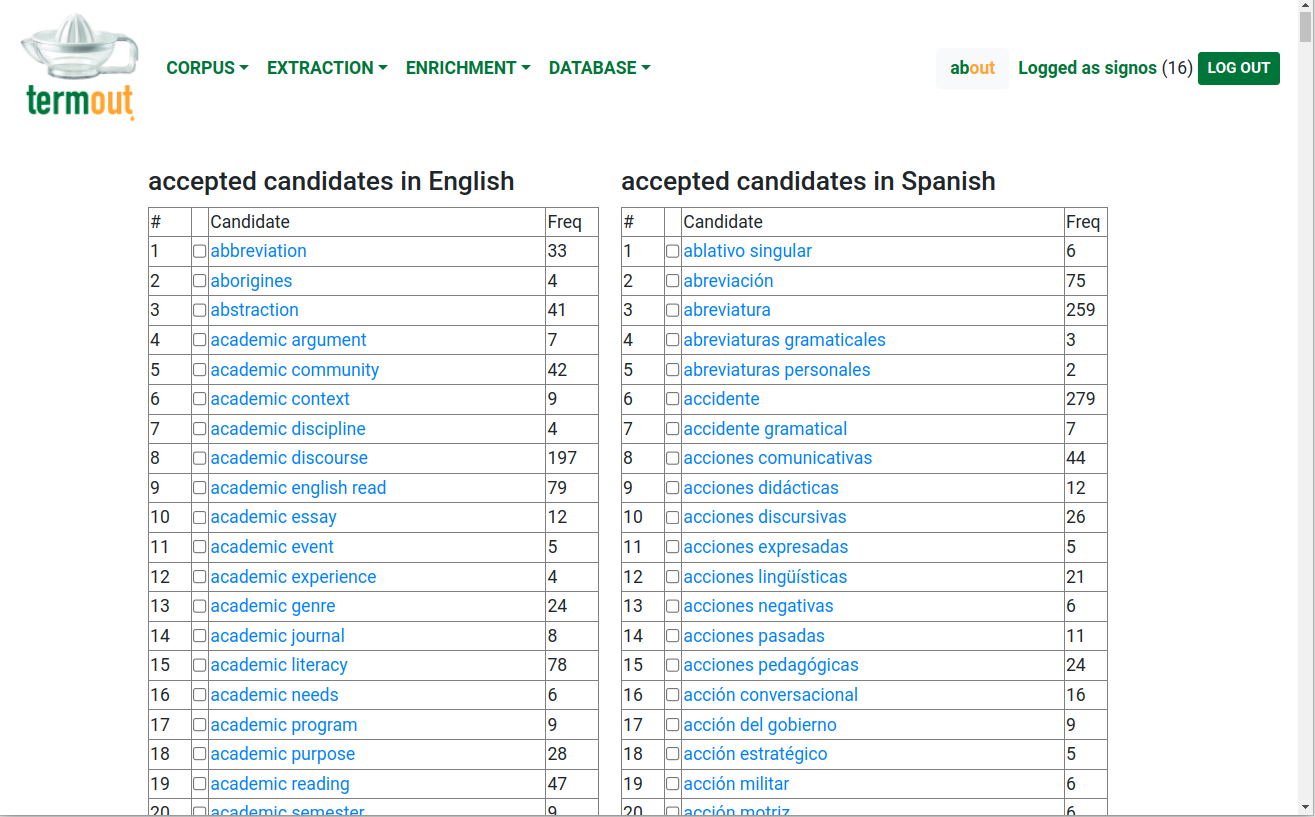
Figure 4: Evaluating the results of the term extraction process
-
Term record: This function presents the terminology record as it currently is in the database. In this program, a terminology record is assigned to a term, not to a concept (i.e., it is a semasiological and not an onomasiological database). As in every terminology database, each record has a number of fields, such as grammatical category, gender, definitions, equivalents in another language, examples of use, among others. The program can try to fill in these database with information automatically extracted from the corpus (some of them later, with the 'enrichment' functions). At any given time, users can edit these entries to correct eventual errors or omissions.
-
Concordances: As usual in this type of programs, Termout also includes a function to retrieve concordances of an expression in the corpus, which can be a single or multiword form.
IV. Information extraction / enrichment
Return
-
Semantic categories: Once the terminology extraction process is finished and the results have been evaluated, users can start to apply the information extraction functions. The first one is the extraction semantic categories. There are currently different possibilities with this module:
- To analyze the semantic field of terms: it will populate the database with the semantic field of each term (i.e., with terms syntagmatically associated).
- To submit the terms to a clustering process: this is used to organize the terminology in semantic fields. The clustering is done with a graph-based co-occurrence algorithm.
- To obtain hypernymy chains: the result consists of a full hypernymy chain for each term in each language, with progressive levels of abstraction. Figure 5 shows an example with terms such as accent, accent mark and accidente, in Spanish. Results are not always correct, but not too bad either, considering that it does not use external sources.
- To obtain a hierarchic graph: after finishing the previous step, one can obtain a large graph with all the terms hierarchically organized (Figure 6).

Figure 5: Semantic categorization of the terms
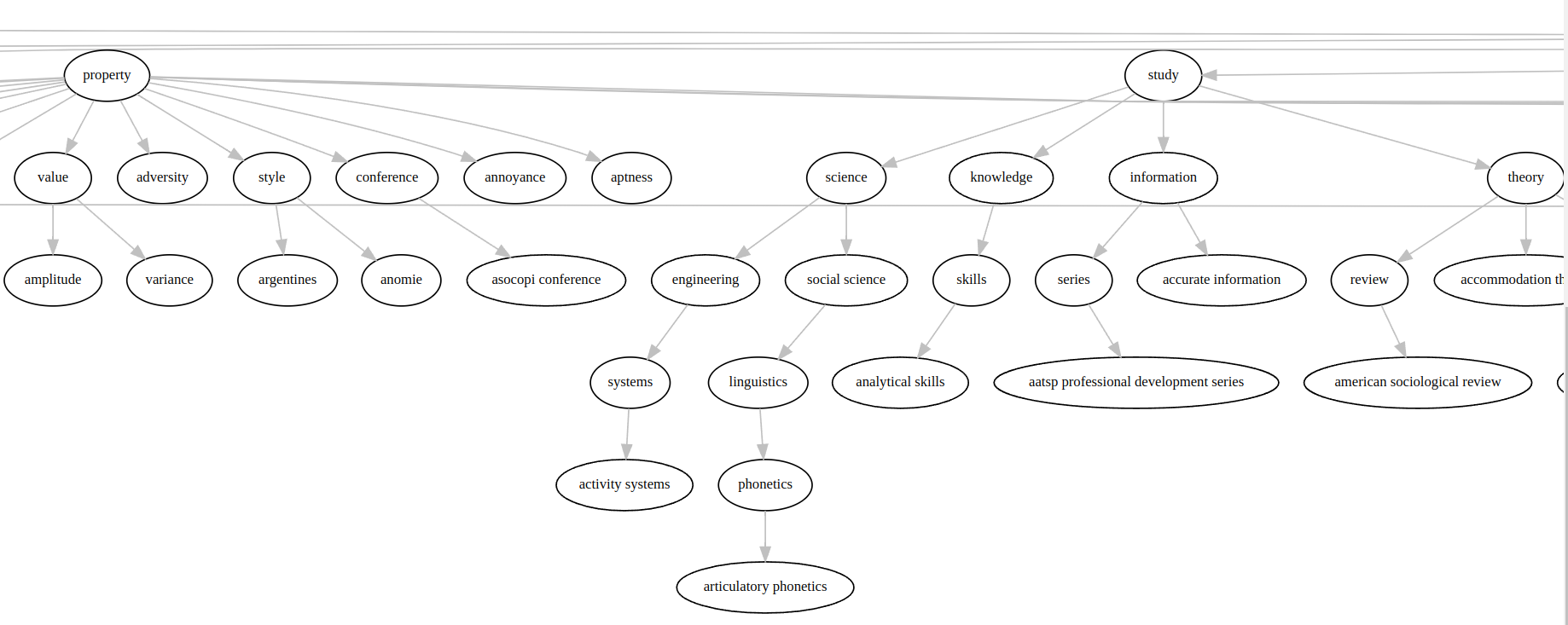
Figure 6: Semantic graph of the terms
In any case, there are two options: 1) to process all terms in the database or 2) to process only a particular term.
-
Definitions: For each term in each language, the program will also attempt to extract definitions found in the corpus. Not always a definition can be found, and sometimes the definitions provided are not useful. However, it is often the case that different retrieved contexts contribute with different relevant attributes that can be crafted into a proper definition. Figure 7 shows how, for each term in the database, some definitions are presented, highlighting important segments.
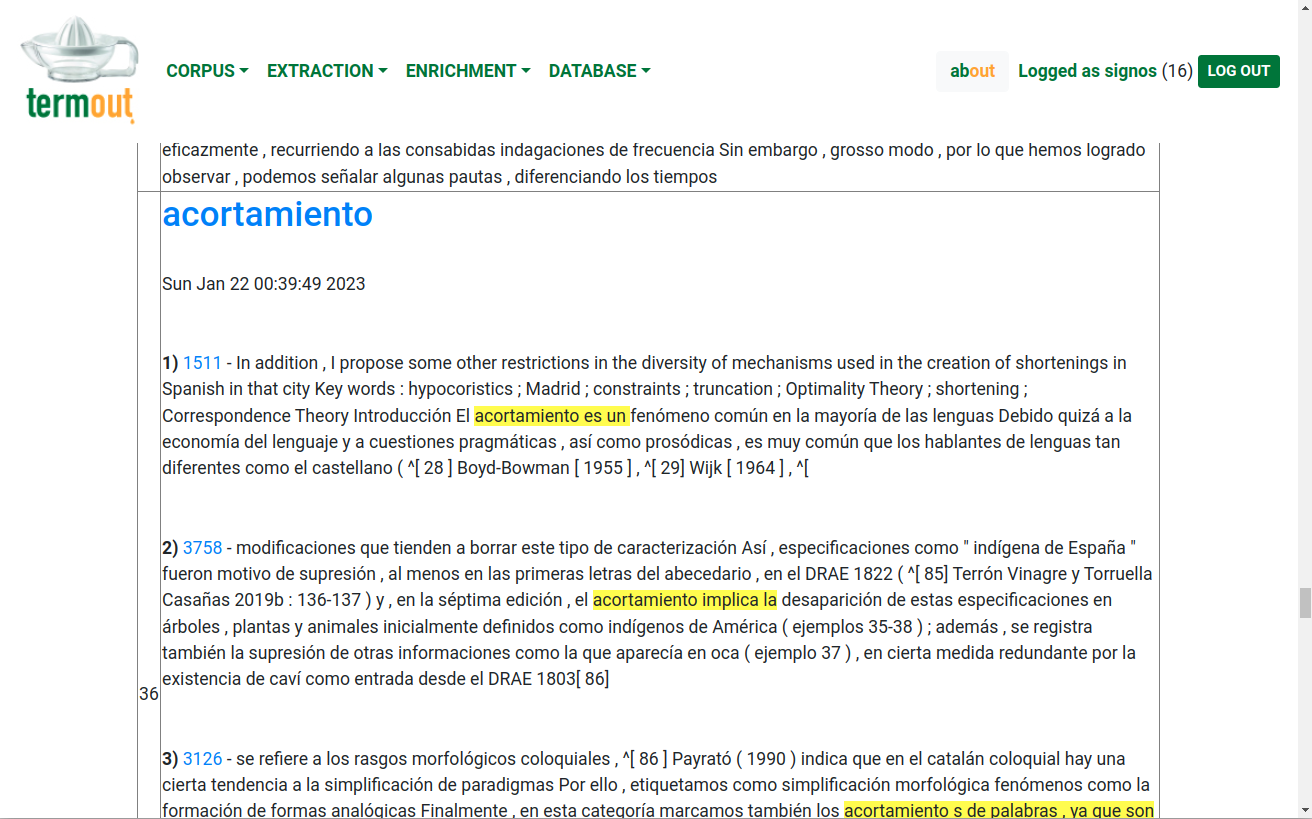
Figure 7: Extraction of definitions from the corpus
-
Bilingual alignment: Termout will attempt to align the lists of terms in each language by using a battery of statistical measures. It is not necessary to provide Termout with a parallel corpora, but ideally one should have documents that have at least fragments of text in another language. This is the case, of course, with scientific journals written in Spanish: they usually have fragments like the title, abstract and keywords in English, as well as a variable number of bibliographic references in this language. Termout takes advantage of the co-occurrence of words of the two languages in the same documents and uses it to compute a series of association measures which also include an orthographic similarity coefficient for the cognates. Figure 8 shows some examples of the alignments. In cases when there is not much certainty, the program also presents some segments where equivalent candidates co-occur, so users can decide for themselves whether the proposed candidate should be retained or rejected.
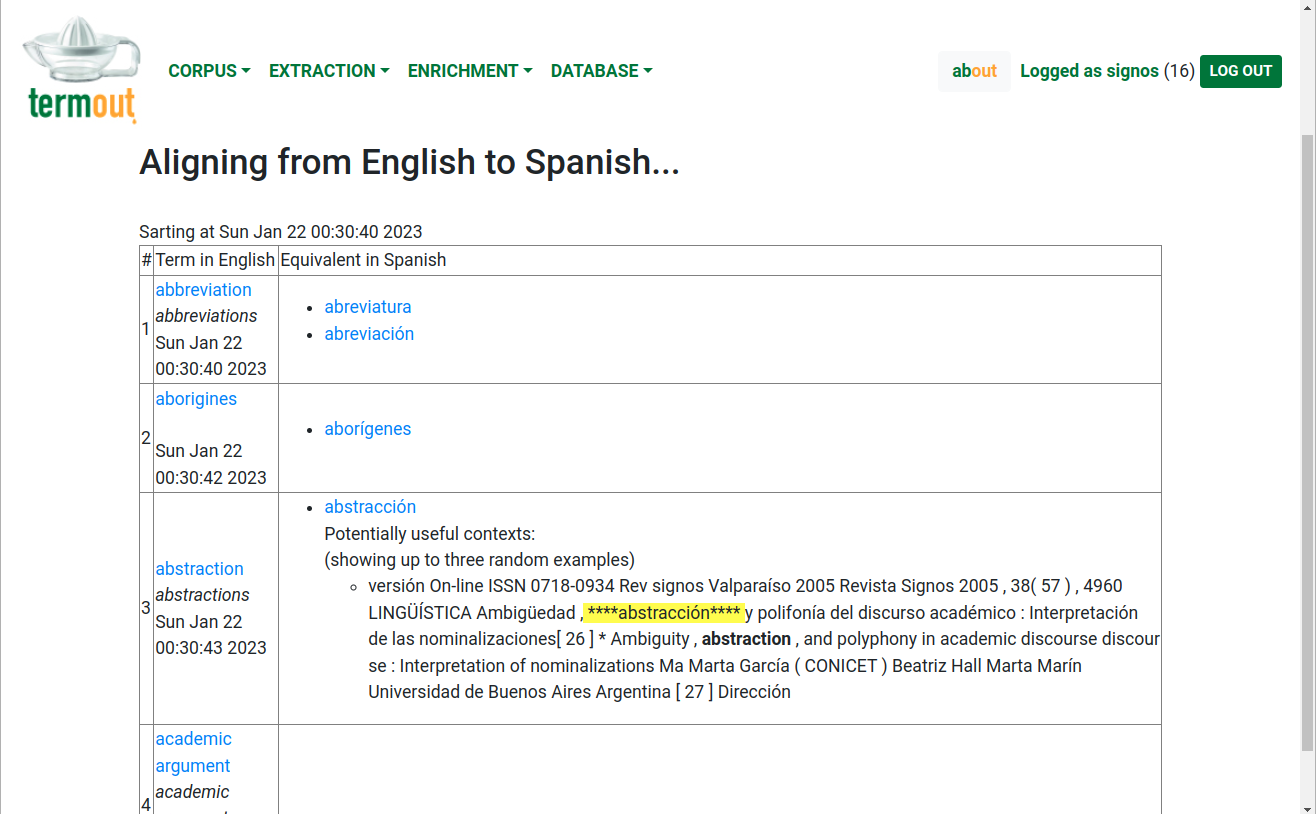
Figure 8: Bilingual alignment of the terms
-
Variants: Once the bilingual terminology alignment has finished, a list of possible synonyms or term variants are presented to the users. Termout considers that two terms in the same language are variants when they have the same equivalent in the other language. Again, results are not perfect. This function, in particular, is
affected by cases of polysemy in one of the languages.
V. Database management
Return
-
Edit: As usual in terminology management software, Termout offers different options for manually editing the terminology database. Users can create new term records, they can destroy them or modify them at any moment.
-
Export: Once the glossary creation is finished and everyone is satisfied with the result, the program will export the glossary in three different standards: CSV, HTML and TBX.
-
Import: Here the user is expected to present a glossary in the TBX standard and Termout will import it to its database, merging it to an existing glossary if any.
Credits: This program was designed and coded by Rogelio Nazar, with the help of Nicolás Acosta for programming. Lexicographers Irene Renau and David Lindemann are acting as advisers, and as beta-testers we have Ana Castro and Benjamín López. Sebastián Márques is our graphic designer, although here we made a mess of his design (it is in the to-do list to restore it to its original splendor). We are the Tecling Group. For more details and other products, check our website: http://www.tecling.com
Comments: If you found a bug or have something to say, please send email to rogelio dot nazar at gmail dot com.
Donate: If you find this tool useful and want to show your support for the cause,
you could send us some cash. That would be greatly appreciated because maintaining this website is extremely expensive. Out of regrettable hippiedom, we give everything away for free, and that of course is detrimental to our finances.
We will do out best to keep this documentation up to date.
|